 热点资讯
热点资讯基于HTML、XML和CSS的多用途Web发布研究

自1990年代初提出概念以来,Web已成为全球内容提供商战略思维的重要组成部分。
但将 Web 定位为内容的传递工具会带来几个问题,包括:发布过程应该如何改变才能利用 Web?内容应该如何表示以支持设备独立性、可搜索性和高效的网络吞吐量?
新兴的 Web 标准可用于实现多用途发布,即在一系列Web设备上呈现相同的内容。
HTML、XML、CSS都可以帮助内容提供商应对在Web上交付内容的一些最重要的挑战:
设备独立性
随着Web的发展,Web设备的数量和范围也在增加。各种尺寸的屏幕、打印机和语音合成器都是用来呈现内容的设备。是否有必要为每个新设备编码内容,或者是否可以采用与设备无关的格式?
内容重要性
为保护投资,内容最好能以多种不同的方式重复使用,搜索引擎必须能够查找索引页面,档案必须是可维护的,并且内容必须采用未来网络设备可以访问的格式。
兼容性强的编码
对于 Web 用户来说,等待页面下载是最令人沮丧的一件事,下载缓慢的主要原因就是使用图像对文本内容进行了编码以保持风格,所以我们必须要找到适合的编码,同时还能保持发布者的风格。
万维网联盟 (W3C) 是一个协调机构,与其 300 多个成员组织合作开发Web的基础技术规范。W3C最近的几项建议以对内容提供者具有重要意义的方式扩展了Web的功能,包括一些涉及HTML、XML和CSS的建议。
结构化文档标记语言
文档的计算机编码长期以来一直专注于保存“最终形式”,例如布局精美的文档。结构化文档格式采用不同的方法,它们不是保留最终形式,而是对文档的逻辑结构进行编码。
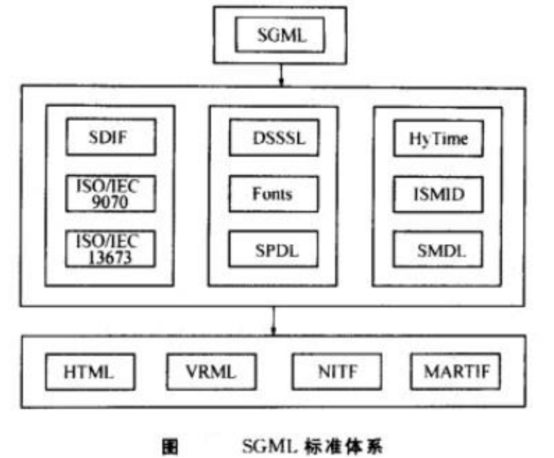
标准通用标记语言(SGML)于1986年成为ISO标准,开创了结构化文档的概念。SGML背后的理念是定义一种通用的元语言,该语言可用于构建特定于应用程序的语言,以对结构化文档进行编码。
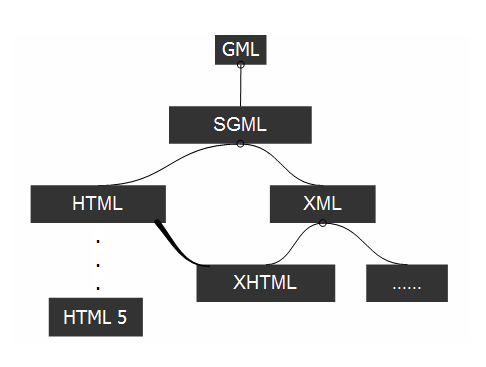
在过去的几年中,结构化文档的工作集中在简化SGML上;其中两项工作是HTML和XML。
HTML起源于瑞士日内瓦的欧洲高能物理实验室(CERN),该实验室于1990年开始了Web项目。当时,HTML为需要通过Internet共享科学文章进行协作的物理学家提供服务。HTML中的语义很少,但为全世界数百万的Web设备所熟知。
HTML在1992年被正式指定为SGML DTD,尽管它与早期Web社区的观点相冲突,但也为HTML规范提供了一个可以进一步扩展的上下文。
SGML 是一项复杂的技术,实现完整的SGML解析器超出了早期Web应用程序开发人员的兴趣,这导致浏览器接受无效文档,因此即使在今天,Web上也很少有文档符合HTML规范。
鉴于HTML元素的功能有限,内容提供商无法轻松地将语义编码到他们的文档中。重新获得SGML在Web上优势的倡议始于1996年,当时成立了一个W3C工作组专门确定适合Web的SGML子集,后被称为XML。
XML包括SGML定义新元素的能力,对于内容提供者,这意味着XML可以比HTML更优雅地编码语义。此外XML消除了必须根据DTD验证文档的负担,XML文档可以引用DTD,但并非必须如此,相反文档可以通过遵循一些简单的句法规则来声明格式良好。
样式表
样式表的概念是对结构化文档的补充,文档包含内容和结构,样式表描述文档的呈现方式。这种分离是与设备无关的文档(所有特定于设备的信息都留给样式表)的要求,并且简化了文档管理,因为样式表可以描述许多文档。
CSS
CERN的CSS工作始于1994年,其目标是为Web开发一种样式表语言,以满足作者对HTML之外的样式控制的要求。1996年,CSS1(CSS的第一级)成为W3C推荐标准,1997年,主流浏览器以及各种创作工具都支持了CSS1。
CSS使用声明性规则将样式附加到元素,一个简单的规则,可能仅用一个P类“警告”,就将所有元素都以白色背景上的红色文本显示:
P.warning {color: red;background: white;}
CSS1支持基于屏幕的格式设置,包括字体、颜色和布局。在样式表出现之前,Web 作者必须制作文本图片来传达颜色和字体。这导致了Web的大部分网络带宽不是用于文本而是用于文本图片。
使用样式表而不是图像还可以提高Web的可访问性,语音合成器可以为盲人用户阅读HTML 编码的文本,文本也可以通过盲文触觉反馈设备呈现。另一方面,图像拒绝非视觉访问。
CSS 的下一级—CSS2,于1998年5月成为W3C推荐标准—通过添加特定于媒体的样式表的概念来增强Web的可访问性。
例如样式表可以描述文档的听觉渲染,如下所示:
@media speech {BODY { voice-family: female }H1 { volume: loud }}
此样式表适用于所有支持语音输出的Web设备。
这种特定于媒体的样式表使设计人员能够仔细描述设备组的表示,同时底层文档保持与设备无关。
手持式Web设备还需要样式表特别注意,因为它们的显示表面很小。
例如,可能没有空间放图片,只应提供文件的缩减版本。下面的样式表关闭了图像和普通段落的显示,所以只显示类“ingress”的段落:
@media handheld {IMG { display: none }P { display: none }P.ingress { display: block }}
CSS 样式表通常在Web设备本身中处理。
然而为了节省移动手持设备的带宽,在固定代理服务器中处理样式表可能是值得的。在上面的“入口”示例中,样式表关闭了图像的显示,因此代理服务器可以阻止移动设备显示图像。这样,节省了宝贵的带宽,并提高了 Web 的感知性能。
进一步提升风格
目前由W3C工作组定义的可扩展样式表语言(XSL)通过能够转换文档结构,使样式表的概念更进一步。例如XSL工作表可以通过从文档中提取所有章节标题来自动生成目录。

使用XSL将XML数据转换为结构化文档,如HTML将在未来几年的多用途出版中发挥重要作用。
随着样式表开发的进展,我们期望通过编程实现的最流行的表示效果将找到它们进入声明式样式规则的方式。例如CSS2包含当鼠标移到元素上时突出显示该元素的功能,到目前为止,这种突出显示只能通过脚本实现。
1997年,W3C发起了一项名为文档对象模型(DOM)的活动,来描述程序和文档之间的接口。它的目标是定义一个独立于语言的应用程序编程接口(API),应用程序可以使用它来访问和修改HTML和XML文档的结构、内容和样式。
在各种网络设备上呈现
具有样式表的结构化文档允许在各种 Web 设备上呈现相同的文档。
事实上,多用途出版的目标是只需要一个足够灵活的源文档以用于不同的环境。但是有时可能需要将文档从一种表示格式转换为另一种表示格式,然后再发布到 Web 上。与实际提供的内容不同的方式来管理内容存在一些问题。
我们的核心主张是HTML和样式表应该足够丰富,可以作为许多出版商的主要文档格式。然而,在传统文档之外,用XML编写的其他数据格式也可以捕获语义。
为未来的应用程序捕获语义,术语“向下翻译”和“向上翻译”经常用于讨论如何将文档从一种格式翻译成另一种格式,向下翻译是指生成的文档具有比原始源文档更少的语义重要标记的过程。
向上翻译是指一个相反的过程,源文档可以是任何格式,并且使用专门的规则来删除面向表示的、通常是专有的标记。目标是具有抽象标记元素的更高级别表示,适用于独立于平台和设备的文档描述。
并且可以被视为多用途发布的准备过程,利用迄今为止可以实现新应用程序的信息内容的价值。而向下翻译通常是一个简单的过程,根据内部规则进行微调,以执行到其他文档格式的实际翻译。
向下翻译过程还必须应对发布时间表的实际要求。
通过向上翻译利用现有信息,并学习以新方式使用新创作工具,或现有工具将代表信息的长期价值所证明的投资,几个场景说明了使用更多语义标记和元数据可能实现的应用程序类型:
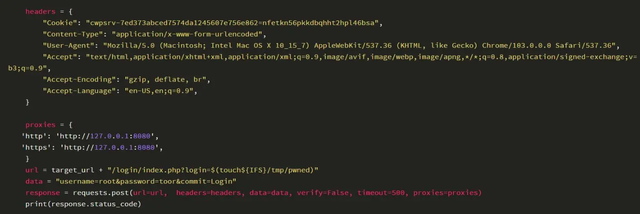
结构化查询
通过URL或搜索引擎查找文档是当今Web上的标准做法,结构化查询将通过允许查询给定的作者或位置来扩展搜索选项的范围。
智能代理
比如用户对某些商品提出报价,然后让他们的代理人在 Web 上找到最好的供应商,用户表示有兴趣购买商品,他们的代理人会搜索并确定最高价格和谈判策略。然后在没有用户干预的情况下,这些代理使用项目描述来查找所有潜在的经销商,并进行财务交易以通知用户明天早上7:00有货物到达
这些场景表明信息在Web上的表示和重用方式还有改进的余地,新Web应用程序的一个重要催化剂将是以机器可理解的形式合并额外的语义。
简单的HTML文档,在增加了样式表,不仅保持了设备独立性和可访问性,同时还提高网了络性能。
对于在 Web 上发布文档的任何人来说,无处不在的HTML很可能成为未来几年的首选文档格式。
今天用户应该希望从他们访问的信息中获得更多,那些创作 HTML 的人可以通过使用 HTML 的完整语义和添加样式表来增强他们的内容,那些在将内容放到Web上之前以其他格式创作内容的人应该确保将其转换为HTML时保留原始语义。
这需要在创作过程中付出额外的努力,但随着新的Web应用程序成为可能而获得回报。XML 允许内容提供者对高度结构化的数据进行编码,因此在设计新的Web应用程序时应该仔细考虑。
一般来说,为了在多用途发布中实现风格效果,建议使用HTML、XML和CSS等声明性数据格式,而不是脚本和小程序。易于转换为其他格式的声明性数据更可能与设备无关,并且往往比程序寿命更长。