 热点资讯
热点资讯流媒体管道的陷阱:分析和性能改进(译文-来自: Lyft)
了解Lyft如何识别和修复我们的流媒体管道中的性能问题。
背景每个流媒体管道都是独一无二的。在审查管道的性能时,我们会问以下问题:“是否存在瓶颈?”、“管道的性能是否最佳?”、“它会随着负载的增加而继续扩展吗?”定期询问这些问题对于避免在最后一刻仓促解决性能问题至关重要。通过这样做,您可以调整管道以实现最佳性能,始终如一地满足SLA,并减少资源浪费。
本文将涵盖以下主题:
绩效改进过程剖析流媒体管道的策略常见性能问题提高性能的一般准则绩效改进过程任何软件系统的性能改进都不是一个独立孤立的任务,而是一个迭代的过程。它包括以下步骤:
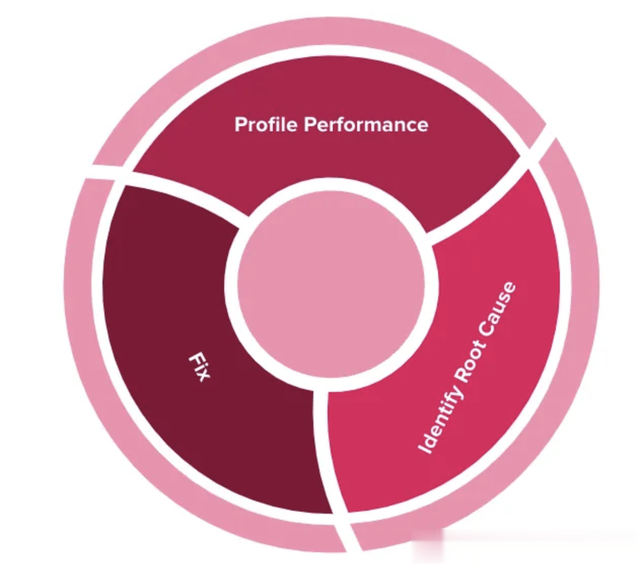
测量/配置文件性能确定根本原因使固定转到第一步重复该过程,直到获得所需的性能(在目标规模上)或用尽所有性能指标。
分析您的管道在没有任何分析工具的情况下识别性能问题是在黑暗中进行的。分析是该过程的第一步,需要正确的工具。工具可帮助您更快地识别影响最大的性能问题。它们还可以与开发环境集成,以在开发生命周期的早期提供综合报告。
内存和CPU分析器将内存和CPU分析与执行环境集成是至关重要的。即使是最微不足道的代码也可能隐藏严重的性能瓶颈。目测代码无助于识别问题,因此拥有一个可以为您提供更准确图片并帮助快速找到根本原因的分析器非常重要。
由于我们的大部分管道都基于ApacheBeam并使用Python中的管道代码,因此我们使用Pyflame和异步分析器来生成CPU使用率的热图。这有助于了解性能特征并识别违规代码。在撰写本文时,Pyflame已被弃用并且不再受支持,尽管存在类似的工具,例如flameprof。
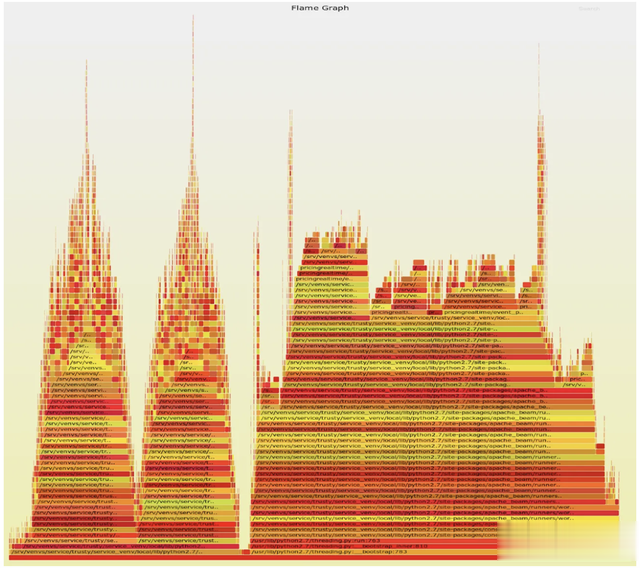
图1:PyFlame图形示例
如果您的管道是基于JVM的,您可以使用各种JVM分析器来识别瓶颈。
Flink仪表盘最近,Flink控制台添加了可视化工具,可以显示各种性能数据点,以便识别性能瓶颈。例如,您可以查看可能导致背压的单个运算符的CPU利用率。此数据在操作员级别表示,可以为您提供限制搜索区域所需的信息。
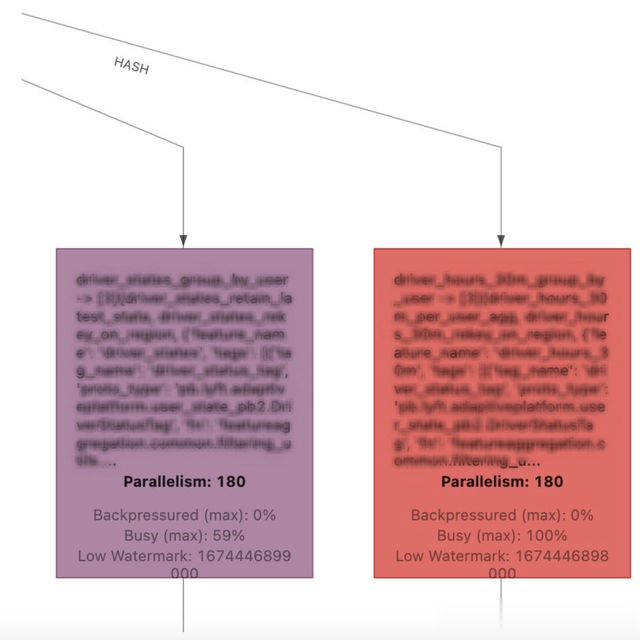
图2:高CPU使用率
正如您在图2中所见,一位操作员100%忙。这可能会导致管道中出现背压。它还提供了宝贵的见解,说明哪些管道运营商需要更仔细地审查以确定任何瓶颈。仪表板提供操作员级别的记录吞吐量,有助于识别管道中的任何数据偏斜(热分片)问题。Flink仪表板还有一个内置的火焰图(图3),可用于识别基于JVM的管道中的瓶颈。可以通过在配置中设置标志来启用此火焰图:
rest.flamegraph.enabled:true
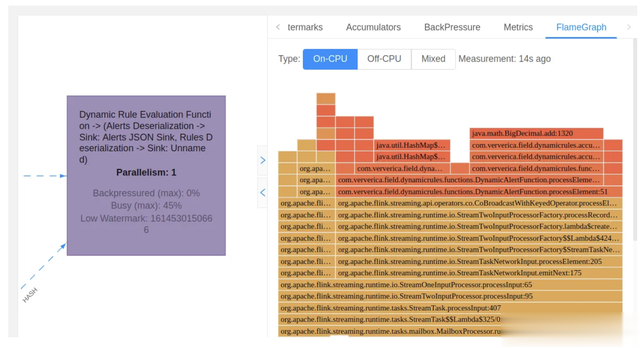
图3:Flink火焰图
Flink的Metrics系统Flink还在任务和运算符级别生成各种系统性能指标:
吞吐量延迟(水印)JVM指标(堆、使用的直接内存、GC等)这些指标可以发送到单独的指标监控系统,以创建一个仪表板(图3)来持续监控性能。

图4:JVM监控仪表板
除了上述指标外,还针对以下指标设置警报:
检查点大小检查点故障管道重启每分钟流水线输出从稳定性的角度来看,这些指标很重要,可以立即发现管道问题。应用程序所有者还可以定义对应用程序的整体健康状况很重要的业务相关指标和SLA。在某些情况下,系统指标可能在范围内,但业务指标却有不同的说法。例如,端到端延迟会显着增加。在我们的案例中,这是由两个因素造成的:1)数据偏斜和2)上游事件生成问题。
常见性能问题在管道操作方面拥有丰富的经验,将它们扩展到每秒处理数十万个事件之后,我们意识到有四类性能问题在管道中很常见。这些问题按严重程度顺序列出:
数据偏度(热分片)大窗口尺寸与低速服务交互序列化和反序列化数据偏度(热分片)数据偏斜或热分片是所有性能问题中最臭名昭著的一个。在80%的情况下,我们将其确定为性能问题的罪魁祸首。这主要是由于单个键上的数据高度集中。它的一些副作用包括增加端到端延迟和资源利用不足。对于此类问题的下意识反应是为流水线提供更多的计算能力,但这并不能解决问题,只会导致资源进一步利用不足。这可以在Flink仪表板的帮助下识别,以仔细识别输入记录分布不均匀的操作员。有关更多详细信息,请查看我们之前关于数据偏度的博文。
大窗口尺寸大窗口大小会在窗口实体化时导致巨大的飞行数据量并增加检查点大小。一些副作用包括增加端到端延迟和不均匀(例如锯齿)资源利用模式。这变得更糟,特别是对于滑动窗口,因为Flink为每个窗口存储数据副本,这增加了整体数据大小,并增加了内存和CPU利用率。
这可以通过查看系统仪表板并使用大窗口仔细识别受影响的操作员来识别。
与更高延迟服务的交互一些用例需要一个管道来与外部服务交互,以存储输出或用额外的数据混合传入的记录。
当外部服务无法跟上时,外部服务交互会带来不受控制的延迟或不确定状态的成本。这个问题的影响是上游运营商的背压和更高的端到端延迟。理想情况下,管道中应避免此类操作。在无法避免的情况下,可以通过为运算符设置正确的并行度并分批执行操作来将影响降至最低。
序列化和反序列化在大多数情况下,序列化和反序列化性能问题显而易见。可以通过查看火焰图来确定问题。在某些极端情况下,我们注意到大约20%的资源利用率可归因于序列化成本,当摄取大量事件时,这种情况会更加复杂。理想情况下,应尽量减少此类操作并将其推到管道边界。
一般准则每个管道都是不同的。没有一种放之四海而皆准的性能改进,但有一些通用的指导方针可能会带来一些快速的胜利。
避免重复操作通常情况下,重复操作会潜入流水线代码中。定期检查重复操作。例如,管道可能具有不同的并行子部分,这些部分可能会一次又一次地反序列化相同的数据。此操作可以推送到上游操作员,因此可以执行一次。
避免不必要的洗牌数据混洗是性能下降的最常见原因。深入了解运算符以及它们如何导致混洗有助于您设计更好的管道。一般准则是尽量减少此类运算符的使用。这可以显着提高性能并减少端到端延迟。
可以使用Flink仪表板识别混洗。每当两个运算符之间的边被Hash或Rebalance表示(图5)时,这意味着数据正在被上游运算符重新洗牌。
通常,Flink会提供发生混洗的方法的名称。如果不需要重新洗牌,则应将其从流水线中移除。流水线设计的高级目标之一是尽量减少流水线中的洗牌次数。

图5:重组或再平衡
启用Cython这特别适用于用Python(ApacheBeam)编写的管道。在我们的案例中,Cython获得了5%的性能提升。在Beam中启用Cython很容易,在构建和执行环境中安装Cython(确保Cython版本≥0.28.1)。
此外,您可以使用Pyflame分析来识别慢速函数并对它们进行cythonize。
尽早删除不必要的数据通常,流式管道旨在处理大量数据,但无论如何处理不必要的数据都会影响CPU、内存和网络利用率的性能。始终遵循最少数据处理的原则。我们在管道的最开始积极地删除不必要的数据或属性。这使我们的绩效平均提高了7%。
使用Protobuf您可能知道,当运营商通过网络发送数据时,延迟会增加。我们试图通过将数据转换为protobuf对象来减少数据大小。Protobuf是一种二进制格式,具有众所周知的模式,因此通过网络传输的数据要小得多。我们使用一条protobuf消息在管道中的运算符中传递数据。
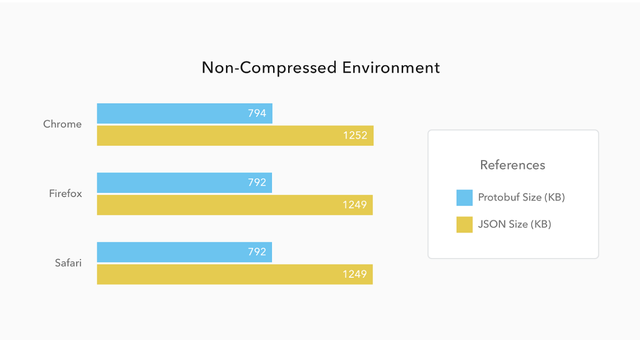
图6:最终大小比较(感谢OAuth)
避免数据偏斜正如上一篇文章(Streamingpipeline的陷阱:数据偏斜)中提到的,尽可能避免数据偏斜。这是阻碍最佳性能和减少资源最佳使用的最常见罪魁祸首。查看之前的帖子,了解有关识别数据偏斜和修复它的想法。该策略的要点是确定分发数据的密钥。尽可能接近统一。例如,基于区域或城市的分片可能会导致数据偏斜(某些城市比其他城市大),而基于用户ID的分片则更有可能统一分布数据并避免数据偏斜。
检查点如果检查点对齐花费的时间超过几秒,检查点也可能是性能下降的来源。Flink会自动取消较长的检查点。频繁的检查点会降低性能,因此,必须找到连续检查点之间的最佳间隔。否则,流水线将大部分时间花在检查点上,而不是进行实际工作。您可以测试各种配置、测量性能并选择最符合您的SLA要求的配置。您也可以尝试未对齐的检查点,它在我们的测试中没有显示出任何负面影响。
此外,监控检查点大小(图7)。避免在状态中存储不必要的数据以减少整体检查点大小。
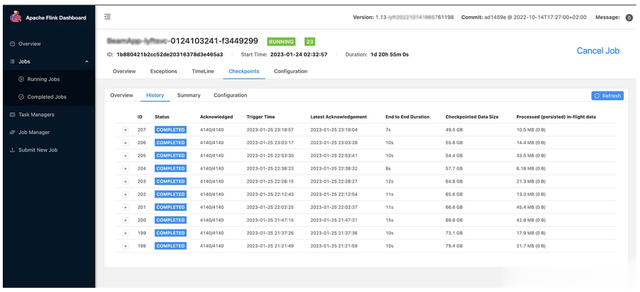
图7:检查点大小的Flink仪表板
较小的状态大小有时需要使用有状态处理,但始终建议保持较小的状态大小。这有助于保持较小的检查点大小并最大限度地减少数据传输。
为了保持较小的状态大小,如果状态与全局窗口相关联,则需要确保定期清除状态。全局窗口是无限的,永远不会实现;因此,状态将永远保存在内存中。这可能会导致内存不足(OOM)崩溃。最好有一些定期清除状态数据的逻辑。
此外,较长的滑动窗口往往具有较大的状态大小,因为每个窗口都有一份数据副本。这增加了整体数据量,因此增加了更大的状态大小。
网络大多数服务都部署在商品硬件上,这些硬件使用多区域和可用性区域(AZ)来提高可用性。然而,流式管道是不同的。它不能部分下降。此外,网络速度是管道性能的重要组成部分,因此管道应该部署在本地(例如到单个AZ)以保持所有实例/任务管理器接近以最小化网络延迟。我们在3个轴上监控管道:延迟、可用性、成本,并根据业务需求优化每个轴。
结束语有多种策略可用于提高性能,但里程可能因数据和管道设计而异。构建管道时,不要预先优化管道。相反,将其视为贯穿管道整个生命周期的迭代过程,并逐渐提高性能。
作者:RakeshKumar
Hi,Iamanengineerwithextensiveexperienceinhighlydistributed&scalablesystems.
出处:https://eng.lyft.com/gotchas-of-streaming-pipelines-profiling-performance-improvements-301439f46412